
微信小程序页面实现分享功能 微信小程序实现页面的分享功能有两种实现方式:: 监听用户点击页面内转发按钮(button 组件 open-type="share"),并自定义转发内容。 使用onShareAppMessage实现页面的分享功能,完整的文档可前往小程序文档中心查看onShareAppMessage 一.使用自定义的分享方式(用户点击页面内的按钮进行分享):在需要分享的页面中添加一个按钮button: 属性为 open-type="share" 在微信小程序的页面的 js 文件中添加一个函数:onShareAppMessage(Object object) 二.使用默认的分享方式在微信小程序的页面的 js 文件中添加一个函数:onShareAppMessage(Object object) 相较于上面的少了添加 button 按钮 代码展示: 12345678910111213141516171819202122232425262728293031323334353637Page({ data: { ac ...
window全局属性name📖 window.name 定义:window.name 是 window 对象的一个 可读写字符串属性。 作用:表示当前浏览上下文(即浏览器窗口或标签页)的名字。 默认值:空字符串 ""。 类型:始终是字符串。 🔑 特点 用于窗口/标签页的标识 当你在 <a target="name"> 或 window.open(url, "name") 里指定的 name 值,就是和 window.name 绑定的。 如果有一个已存在的窗口/标签页的 window.name 值等于 "myWin",那么 window.open(url, "myWin") 就会在那个窗口里打开。 如果没有,就会新建一个窗口,并把它的 window.name 设置为 "myWin"。 持久化特性 window.name 的值在 页面跳转时不会丢失(即使跳转到不同域名的页面,值仍然保留)。 这在以前被用来做 跨页面数据传递。 ...

JavaScriptPromise 一.数据结构1.JavaScript 有哪些数据类型共有八个数据类型,分别是undefined,Null,Boolean,String,Number,Object,Symbol,Bigint 这些数据类型可以分为原始数据类型与引用数据类型(复杂数据类型),他们在内存中的存储方式不同 其中 **Symbol** 和 **BigInt\*\* 是 ES6 中新增的数据类型: **Symbol**代表创建后独一无二且不可变的数据类型,它主要是为了解决可能出现的全局变量冲突的问题。 **BigInt** 是一种数字类型的数据,它可以表示任意精度格式的整数,使用 BigInt 可以安全地存储和操作大整数,即使这个数已经超出了 Number 能够表示的安全整数范围。 堆: 存放引用数据类型,引用数据类型占据空间大、大小不固定。如果存储在栈中,将会影响程序运行的性能;引用数据类型在栈中存储了指针,该指针指向堆中该实体的起始地址,如Object、Array、Function。栈: 存放原始数据类型,栈中的简单数据段,占据空间小,属于被频繁使用的数据,如Str ...

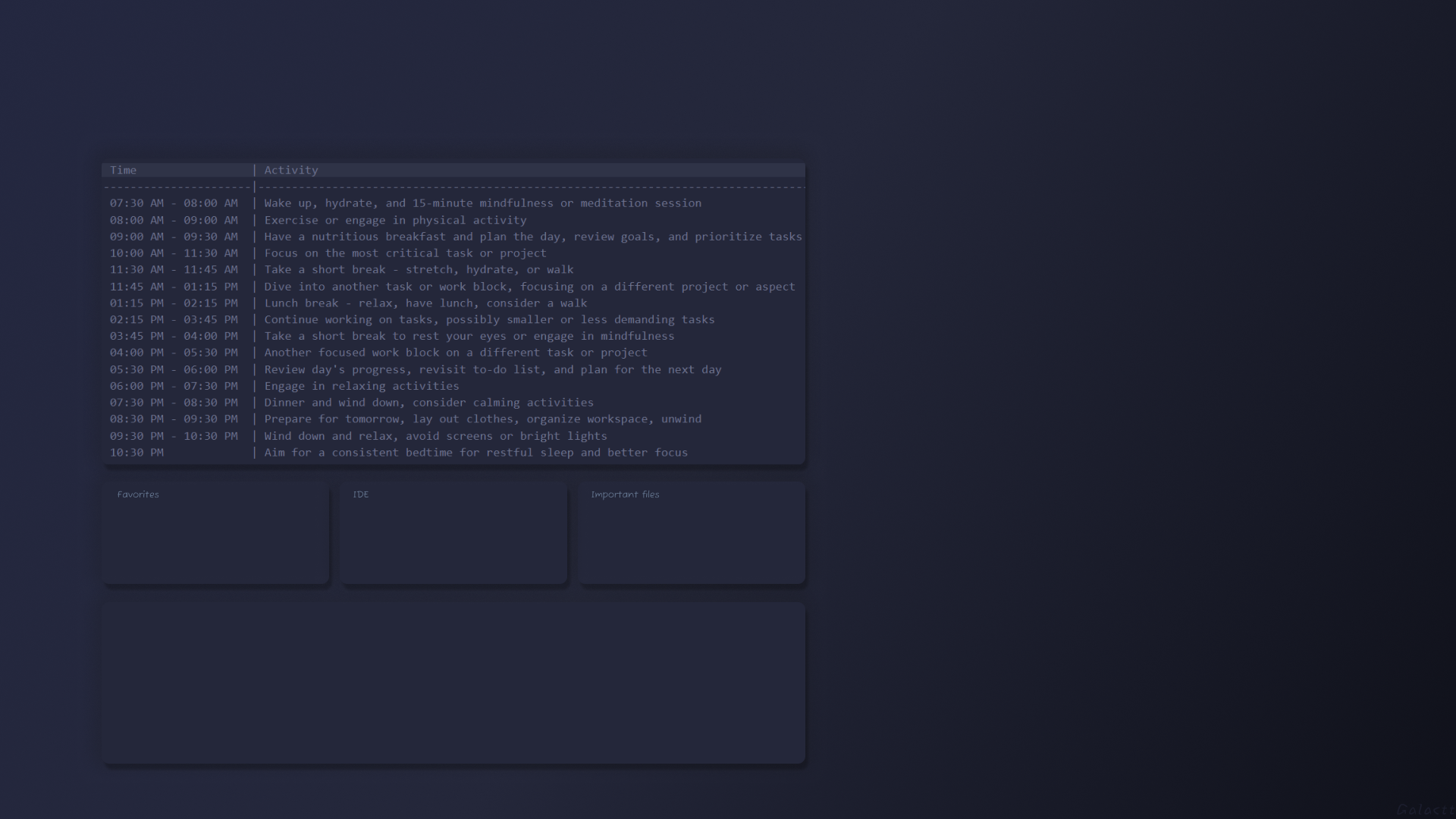
项目复盘
未读cst-exam一.项目基本架构:1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465666768697071727374757677787980818283848586878889src/├── routes/ # 页面级路由│ ├── login/ # 学生登录页 -> /login│ │ └── +page.svelte│ ││ ├── teacher/ # 教师模块 -> /teacher│ │ ├── login/ # 教师登录页│ │ ├── 其他页面/ # 教师子页面(例如试卷、成绩等)│ │ ├── +page.svelte│ │ ...

react安装react项目: 1npx create-react-app your-project-name 启动项目: 1npm start jsx: JSX(JavaScript XML)是一种在 React 中使用的语法扩展,它看起来很像 HTML,但实际上是 JavaScript 的一种语法糖。JSX 使得编写和读取组件的结构更加直观,就是 JavaScript 和 html 的缩写. 可以在 js 代码中编写 html 代码 jsx 不能在浏览器中进行运行,而是需要一个解析工具进行解析之后才能够进行运行 语法通过{}的形式来展示数据 12345678910111213141516const username = "admin";const numbwe = 123function App() { return ( <div className="App"> {username} {numbwe} {' ...
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106<!DOCTYPE html><html lang="en"> <head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <title>Document</title> <link href="https:// ...

1. 概述 Svelte 是一个前端框架,专注于编译时优化,区别于 React 和 Vue,它通过在编译时将组件转化为高效的 JavaScript 代码,消除了虚拟 DOM 的性能开销。 响应性:数据变化会直接影响视图,Svelte 利用编译时的静态分析自动处理组件的更新和重新渲染。 无框架运行时:Svelte 生成的代码没有框架运行时,这使得生成的应用体积小、性能高。 2. 基础概念 Svelte 文件:每个组件是一个 .svelte 文件,包含三个部分:HTML、JavaScript、CSS。 HTML:组件的结构和模板。 JavaScript:组件的逻辑和数据。 CSS:样式表,支持局部样式。 组件:Svelte 的应用由多个组件组成,每个组件是独立的封装单元。组件间可以通过 props、events 和 store 进行交互。 编译过程:在开发时,Svelte 会将 .svelte 文件中的代码转化为高效的 JavaScript,减少运行时依赖,减少浏览器负担。 3. 响应式设计 响应式声明(Reactivity):Svelte 使用编译时的响应式语法,不需要手动管理依 ...
###全局属性 app.json 配置文件结构 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778{ "pages": [ "pages/index/index", // 启动页,进入小程序时首先展示的页面 "pages/logs/logs" // 第二个页面,通常用于展示日志或其他信息 // ...... ], "window": { "navigationBarBackgroundColor": "#ffffff", // 导航栏背景色,通常设置为白色或主题色 "navigationBarTitleText": "我的小程序", ...

C/C++
未读stack(c++)<stack> 是 C++ 标准库中的一个容器适配器,提供了一个后进先出 (LIFO) 栈的实现。 1. 引入头文件1#include <stack> 2. 声明与初始化12stack<int> s; // 创建一个存储 int 类型的栈stack<string> ss; // 创建一个存储 string 类型的栈 3. 常用方法 方法/成员 作用 复杂度 示例代码 push(val) 将元素 val 添加到栈顶 O(1) s.push(10); pop() 移除栈顶元素 O(1) s.pop(); top() 返回栈顶元素的引用,但不移除 O(1) int topElem = s.top(); empty() 判断栈是否为空,返回 true 或 false O(1) if (s.empty()) { /* do something */ } size() 返回栈中元素的个数 O(1) cout << s.size(); sw ...

prim1234567891011121314151617181920212223242526272829303132333435363738394041424344454647#include<iostream>#define max_number 9999using namespace std;typedef struct Graph { int vexsnums;// 表示顶点的个数 int arcsnums;// 表示边的个数 int arcs[20][20];// 边的信息 char vexs[20];// 顶点的信息};typedef struct CloseEdge { // 定义一个辅助的数组 char vexs;// 记录顶点 int weight;// 记录这个顶点到这个已经有的树的最小距离};CloseEdge* InitCloseEdge(Graph* G, int indexnumber) { // 初始化这个距离prim树最小距离 CloseEdge* closeedge = new CloseE ...




